


本記事は2021年6月5日にJosh岁氏が投稿した記事の翻訳版です。
パート1では,Nutanix横穿が分散ストレージファブリック(ADSF)注册により,ノード障害からレジリエンシーファクター2 (RF2)の状態に高速かつ効率的にリビルドする機能について説明しましたが,パート2では,ストレージコンテナをRF2からRF3に変換して耐障害性をさらに向上させる方法と,そのプロセスがどれだけ高速に完了するかを紹介しました。
(今回も)パート2と同様に,12ノードのクラスタを使用しており,ノードごとのディスク使用量の内訳は以下の通りです。
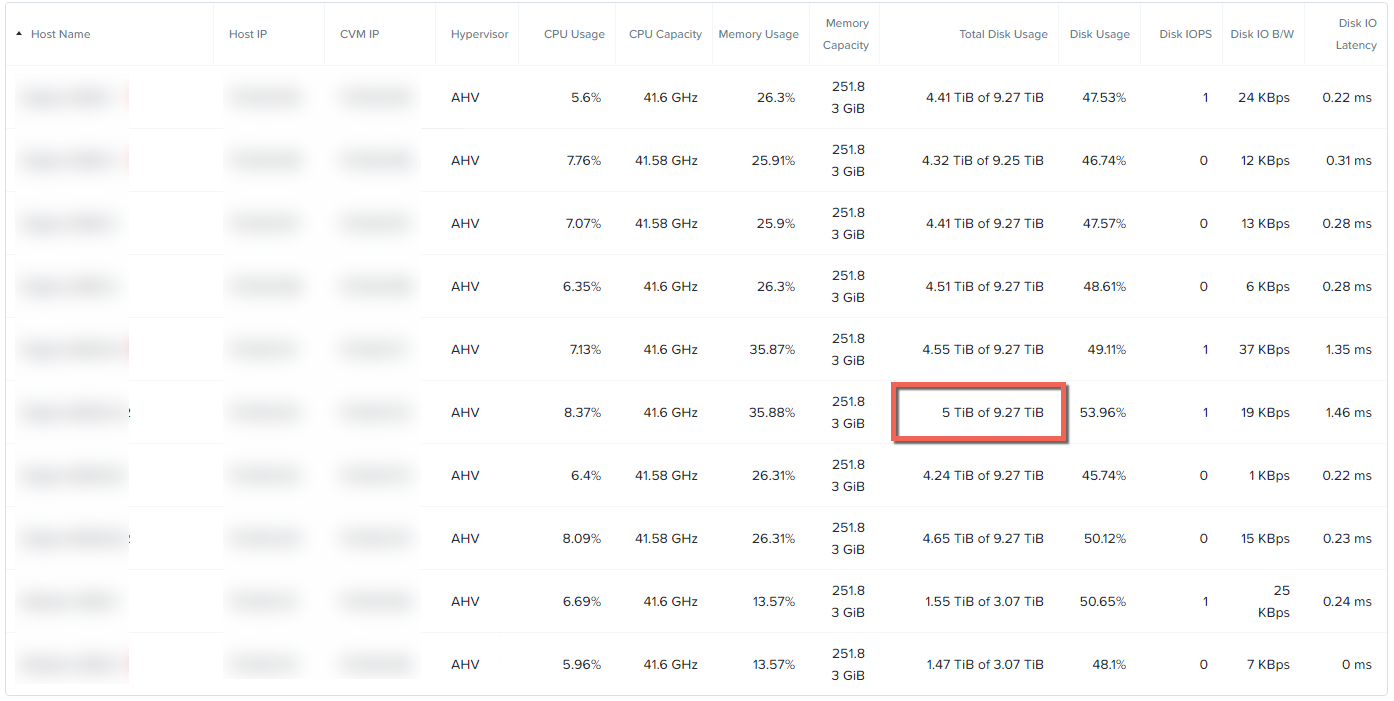
今回障害をシミュレートするノードのディスク使用量は5で结核病,パート1のノード障害テストでの容量とほぼ同じです。なお,クラスタが12ノードになったことで,パート1と比べて(パート1では16ノードを利用)読み書きするコントローラが少なくなっています。
次に,ノードのIPMインターフェイス(IPMI)にアクセスし,“关机,直接(即時の電源オフ)“の操作を実行してノード障害をシミュレートしました。
以下は,ノード障害時のリビルドが約30分で完了し,5结核病のデータの再保護が完了した際のストレージプールのスループットを示しています。
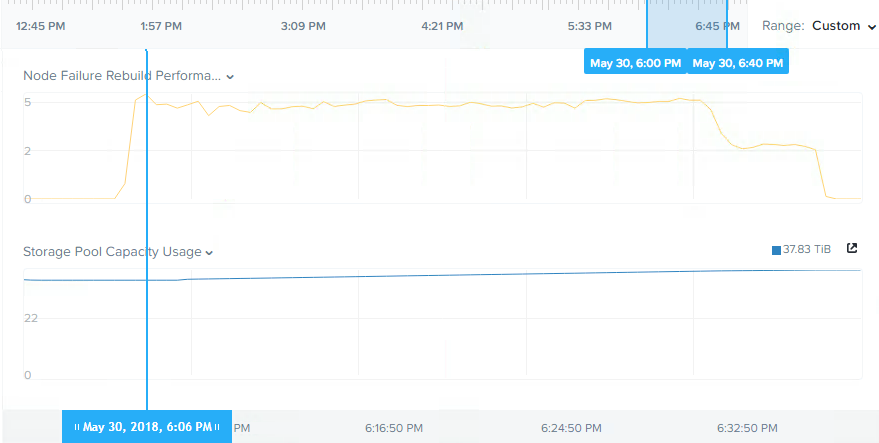
パッと見5年以上前のハードウェアで5结核病のデータの再保護が約30分で完了したことは,圣や他のHCI製品と比較しても非常に素晴らしいことですが,(Nutanixのリビルドは)もっと速くなるはずだと感じたので,少し調べてみました。
その結果,ノード障害をシミュレートした時点でクラスタ(を構成する各ノード上のデータ量)のバランスが崩れており,(障害状態をシミュレートしたノードに比べて)他のノードにデータがほとんどないため,通常の状況のようにリビルドに貢献できなかったことがわかりました(リビルド時の読み取りの観点から)。
クラスタがアンバランスな状態になっていたのは,(ここまでで)ノード障害のシミュレーションを頻繁に繰り返し行っており,ノード障害のシミュレーションを行う前に,クラスタにノードを追加した後にディスクバランシングが完了するのを待たなかったためです。
通常,ベンダーは最適ではないパフォーマンス結果を掲載することはありませんが,私は透明性が重要であると強く感じており,可能性は低いものの,クラスタがアンバランスな状態になることはあり得ます。そして,このようなシナリオにおける回復力への影響を理解することも重要だと考えています。
ここまでのテストでクラスタがアンバランスな状態でのリビルドパフォーマンスを確認しましたが,今度はクラスタがバランスの取れた状態になっていることを確認し,テストを再実行したところ,以下のような結果が得られました。
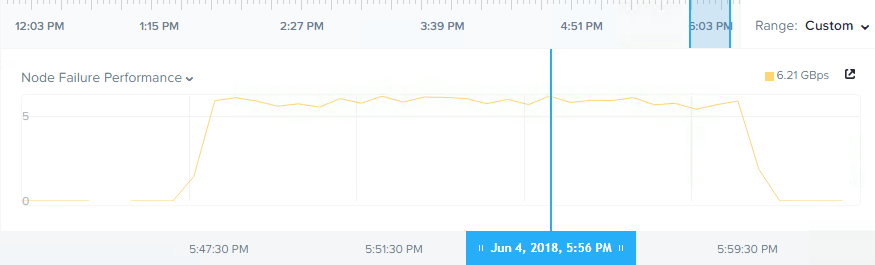
スループットが約5 gbpsから6 gbps以上に向上し,1 gbps以上の改善が見られ,(リビルドにおけるスループットの)持続時間は約12分でした。また,アンバランス環境で見られたようなスループットの低下は見られませんでした。これは,すべてのノードがバランスの取れた量のデータを持っていたため,すべてのノードがリビルドに参加できたことによるものです。
まとめ:
- Nutanix RF3はRAID6(またはN + 2)スタイルのアーキテクチャよりもはるかに耐障害性に優れています。
- ADSFは注册継続的にディスクスクラビングを行い,データの整合性に問題が発生する前に根本的な問題を検出して解決します。
- ドライブやノードの障害からのリビルドは,クラスタ内のすべてのドライブとノードを使用した効率的な分散処理です。
- 4.5结核病を超えるノード障害(このケースでは,6台のSSDが同時に故障した場合に相当)からの復旧にかかる時間は約12分です。
- (最初のテストのように)バランスの取れていないクラスタでも分散してリビルドを行い,短時間で障害から回復できます。
- 通常のバランス構成で稼働しているクラスタは,分散ストレージファブリック(ADFS)に組み込まれたディスクバランシング,インテリジェントなレプリカの配置,データの均等な分散により,障害からより早く回復することができます。