


这篇文章的作者是Gabe Contreras,企业架构师Nutanix
对于许多像Elasticsearch这样的大数据应用程序,人们总是会问这样一个问题:“为什么在Elasticsearch层有RF2,而在Nutanix层仍然需要做RF2 ?”
在操作上,有很多原因让您想要在Nutanix上进行Elasticsearch,特别是在AHV上,而不是在裸金属上。那些操作上的原因,例如没有应用程序竖井、利用空闲的计算和存储、为所有工作负载使用一个窗格和支持一个平台,都可以提高操作效率,特别是在规模上。这些可以帮助你把你的大数据部署变成私有云,为所有的应用程序,并允许你使用空闲的容量来处理工作负载,例如额外的计算来运行kafka消费者和生产者。
还有节省空间的功能,如Nutanix上的压缩和EC-X。Elasticsearch具有压缩功能,因为它包含每个数据节点,而Nutanix可以节省更多的压缩时间。在这篇文章中,我们将关注一个关于RF水平的技术问题,当你有一个应用程序有能力做自己的RF时,重点是Elasticsearch。这些细微差别直接影响到弹性,特别是每个平台在失败时如何处理重建。
首先,让我们回顾一下两种主要的部署模式,我看到客户使用关键的Elasticsearch工作负载进行裸金属部署。这些工作负载几乎总是在闪光灯下。第一个是只依赖Elasticsearch来获取弹性。这意味着RAID 0配置中的裸金属节点可以从每个节点获得最大的性能,但Elasticsearch设置为RF3。这意味着一正本两副本。另一种方法是创建更多节点弹性。这意味着节点上的RAID 10, Elasticsearch上的RF2。使用RAID10配置,您将不需要为单个磁盘故障重建整个数据节点。
Elasticsearch上使用多个副本的另一个原因是为了实现搜索并行化。除非你在做大量的搜索,对许多客户来说,一个主搜索和一个拷贝通常就足够快速搜索了。这表明Elasticsearch的复制结构更多的是关于弹性的。使用Elasticsearch,您可以应用称为节点或机架感知的RF弹性,这将对应于我们为大型部署建议客户在Nutanix上构建Elasticsearch的方式。您可以使用id设置在两个独立的Nutanix集群之间平均分割Elasticsearch节点,以构建跨机架或可用性区域的弹性。
我们将介绍主要的故障场景,以展示每个平台如何处理这些故障,以及Nutanix如何做得更好。
长时间节点失败
第一个场景是一个完整的服务器硬件故障,节点可能会停机几天,直到一个部件被更换。Elasticsearch有设置index.unassigned.node_left.delayed_timeout,该设置的默认值是一分钟。在裸金属环境中,许多客户将此设置为默认值,因为如果节点出现故障,他们希望尽快开始重建。但有些人认为这是5分钟左右的延迟,以给一点额外的时间。Elasticsearch将等待满足此阈值,然后开始重新分配用于重建的分片。
重建在每个碎片级别上完成。对于大型部署,您可能将您的分片设计为最大50GB。因此,如果您有100个需要重建的分片,每个分片都是一对一的复制,一个节点拥有主节点,它将把数据复制到新分配的辅助节点。因此,根据节点的繁忙程度,这种行为可能会导致速度变慢。如果碰巧有一个节点是需要重建的3个分片的主节点,那么这次重建将需要1到3个副本。
这会导致您的环境中出现热点,这会降低索引速度,也会降低搜索速度,因为重建过程占用了更多的资源,需要搜索的副本更少。如果这发生在您的高峰时间,它可能会导致糟糕的用户体验或可能的其他失败。当我们查看客户的生产工作负载时,所有闪光裸金属集群的重建时间为8小时或更长,直到集群健康为止。在高峰时期,重建时间可能会增加到16小时以上。
重建过程和速率由Elasticsearch控制。当重建在后台进行时,数据持久性受到了影响。可以调整Elasticsearch重建数据的速度,但您还必须针对峰值工作负载进行计划。因此,如果您计划在高峰时间重建,然后在空闲时间重建,那么重建速度就会受到人为的限制。
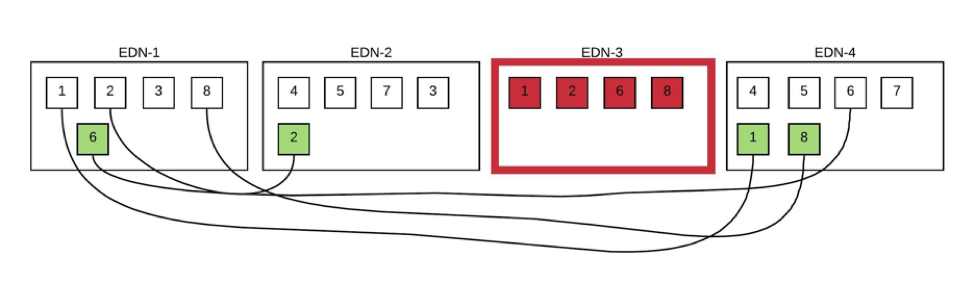
在上面的数据节点故障场景中,在重建期间,数据节点1上有一个热点,因为它有需要重建新副本的4个分片中的3个分片。此外,集群需要保持自己尽可能的平衡,以便它将一个分片复制到节点1。
让我们看看相同的场景,将Nutanix作为底层平台而不是裸金属。对于index.unassigned.node_left.delayed_timeout,我们希望将其设置为15分钟,因为在Nutanix上,我们希望VM能够恢复并恢复,而不是等待它停止工作,并且不希望Elasticsearch过早地重建。我们还使用另一个设置“index.translog.retention.size”。此设置的默认值是512mb,我们将其设置为10gb。这有助于在失败时执行基于操作的同步,这比基于文件的同步要快得多。在Nutanix集群中,Elasticsearch数据节点出现了物理硬件故障。
只需几分钟,虚拟机就会在另一个节点上重启,只要您将Elasticsearch服务设置为自动启动,那么该节点就会被主节点识别为备份节点。由于数据节点只下降了几分钟,任何不活跃的摄入指数几乎立即变成绿色,将是健康的。我们将评估积极摄取的指标,但应该使用我们更改过的设置,并在10-15分钟内将所有碎片标记为绿色。Elasticsearch将在20分钟内显示您在应用程序级别拥有一个完全健康的集群,这意味着您将有两个副本可供搜索。
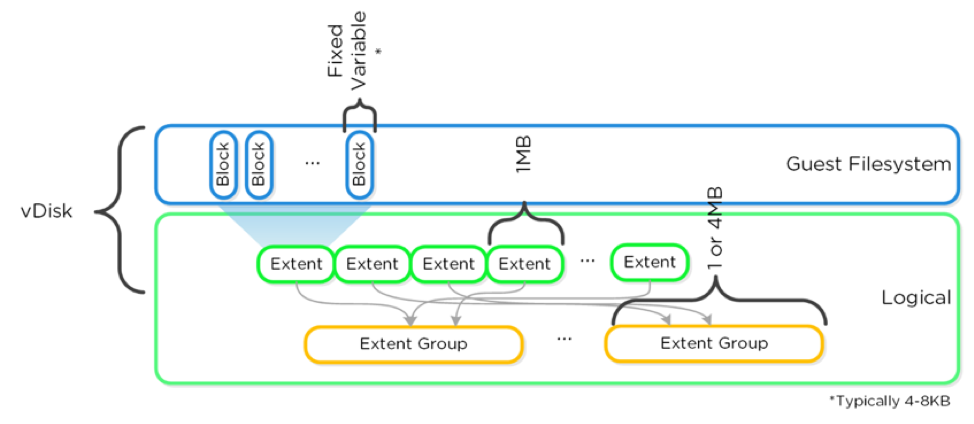
现在,在Nutanix那边会发生什么来重建数据呢?在我们的存储层,我们将数据存储在所谓的区段中。我们的区段可以是1MB也可以是4mb。存储并不知道你的分片是50GB,也不在乎,它已经把它分解成1MB的区段。由于数据局部性,我们将一个副本保存在本地,而其他区段分布在Nutanix集群的其他部分。假设我们有一个32个节点的集群,其中这个硬件节点发生故障,现在只剩下31个节点。
所有31个节点都将参与这次重建,将相同的50GB碎片分割到所有这些1MB的区段中,不仅可以使用所有31个节点进行重建,还可以使用集群中的每个驱动器。由于此重建是完全分布式的,因此出现任何热点的可能性较小,也不太可能干扰您的生产工作负载。这种真正的分布式重建也意味着我们可以更快地重建缺失的数据。使用与客户裸金属节点相同的数据量,我们在3小时或更少的时间内重建了数据。在此重新构建过程中,您的应用程序是完全健康的,在具有与故障发生前相同的性能时,不需要注意重新构建。
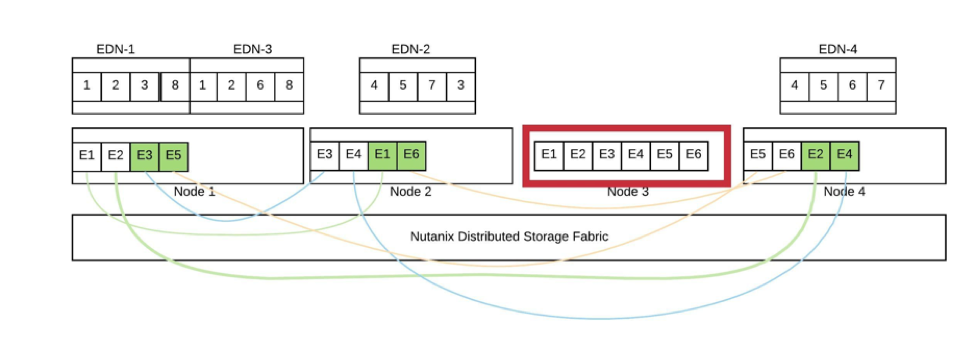
在上面的图表中,Nutanix上虚拟化的Elasticsearch,我们将一个分片分解为用e#标注的区段。在此失败中,Elasticsearch数据节点都是健康的,集群将显示为绿色。而在Nutanix层,在节点3上有一个主副本的区段被重建。这些区段的副本均匀地分布在集群中,重建也是均匀分布的。由于我们将碎片分解成更小的存储区,因此在重建过程中更容易平衡50GB的碎片。
让我们看看另一种类型的故障,瞬态故障。对于这个故障,我们会说硬件出现了故障,宕机了20分钟。裸金属会发生什么?再次命中node_left阈值,Elasticsearch启动重建过程,并开始为重建分配分片。20分钟后,该节点恢复在线,但重建已经开始,因此主节点将该节点上的所有分片标记为过时的并删除它们。现在,该节点完全健康,但处于在线状态,并已重新添加到集群中。在裸金属环境中,您将不得不经历整个重建过程,但现在您将添加另一个任务。
当重建完成且集群健康时,它将不平衡,因为有一个节点上没有分片。现在集群必须重新平衡并开始将碎片复制到该节点。对于一个短暂的故障,可能需要花费许多小时的额外IO来重建和重新平衡,这也会导致出现热点。您可以调整重建和重新平衡以控制它,但这是一个手动过程。您必须花时间查看统计数据并为高峰时间制定计划,而不是将其动态化,并能够根据负载完成重建和重新平衡。
瞬态节点失败
让我们看看Nutanix如何处理相同的瞬时故障。同样,在上面的Nutanix场景中,一切都与长期失败相同。数据节点将重新启动,并且应该很快恢复为绿色。然而,后端Nutanix存储与Elasticsearch处理此问题的方式不同。Nutanix将立即开始数据重建,但不同的是在重建期间节点恢复在线时。由于节点仅仅宕机了20分钟,所以只重建了部分数据。我们将扫描Nutanix节点,看看区段是否仍然相关。
如果它们是相关的,那么我们将停止重建,并将这些区段返回到集群中,并将节点列为健康节点。那已经重建的部分呢?嗯,我们知道现在有一些区段有三份副本,我们将继续,并在下次馆长扫描时标记第三份副本,以便删除。由于我们处理这个短暂失败的方式,我们已经停止了重建tb级数据和重新平衡的需要。这节省了几个小时的额外IO和可能的应用程序性能下降。
当然,Nutanix文件系统还帮助了其他一些故障场景,比如我们的软件和RAID之间的差异。与RAID 10不同,Nutanix上的驱动器故障不需要立即更换就能重建数据。此外,RAID重建缓慢且通常严重影响服务器性能的问题不会影响到Nutanix,因为我们的重建分布在所有节点和磁盘上。
这表明,随着操作效率的提高,Nutanix可以为Elasticsearch提供更一致的性能体验,即使在出现故障时也是如此。
 2019 Nutanix, Inc。保留所有权利。本协议中提到的Nutanix、Nutanix标识和其他Nutanix产品和特征均为Nutanix, Inc.在美国和其他国家的注册商标或商标。此处提及的所有其他品牌名称仅供识别之用,且可能为其各自持有人的商标。
2019 Nutanix, Inc。保留所有权利。本协议中提到的Nutanix、Nutanix标识和其他Nutanix产品和特征均为Nutanix, Inc.在美国和其他国家的注册商标或商标。此处提及的所有其他品牌名称仅供识别之用,且可能为其各自持有人的商标。