


当涉及到在任何平台上运行Elasticsearch时,根据你的用例,获得正确的设置可能需要时间。吞吐量小的部署可能已经部署在云中,但是部署在一分钟处理数百万个文档的情况又如何呢?许多公司在裸金属上运行这些更大的部署也就不足为奇了。许多Nutanix客户已经在我们的企业云上运行了Elasticsearch。我们的客户发现了以下好处:
- 快提供
- 简化基础设施
- 改进可用性
- 更大的灵活性
- 提高效率
- 对于Nutanix客户,能够更好地管理和运行大数据应用和一般服务器虚拟化是一个主要因素。
- 消除支持多个孤岛的需要并为这些工作负载部署虚拟化允许它们获得更好的效率。
- 迁移到Nutanix可以帮助应用程序团队提高可用性,包括如何从可能的中断中恢复Elasticsearch。我们已经多次演示了对Nutanix和Elasticsearch设置进行优化的能力。
- 配置的时间大大减少了,因为在获取裸金属和完成配置步骤之间不再需要等待时间。
该解决方案已设置为保持至少1周的索引,这意味着存储至少200TB的数据总数。这也必须考虑每天对此数据的数百万次搜索。在这种情况下,数据将流入来自Kafka的Elasticsearch。
Elasticsearch是一个IO密集型应用程序,我们设计的目的是合并,这样做可以大大提高IO和吞吐量。
在Nutanix上虚拟化Elasticsearch
下面是对Elasticsearch (ES)环境的总结
单独的机架中的2x 24节点集群(每个机架 - 努力和ES故障域)。每个群集都可以使用其他工作负载运行
- 每个集群使用RF2提供230TB的可用存储
- 每个Nutanix计算节点32核和512GB RAM
- RF2在Nutanix上

Elasticsearch VM配置
- 3管理员节点
- 6摄取节点
- 90年的数据节点
虚拟机磁盘布局:每个LVM虚拟机新增8个vdisk,条带1MB,总容量3.4TB
我们对Linux操作系统应用了一些设置来优化它,以保持IO流向我们的存储子系统。
- Max_sectors_kb = 1024
- nr_requests = 128
- vm.dirty_background_ratio = 1
- vm.dirty_ratio = 40.
Elasticsearch测试
测试完成时,Kafka数据被重定向到Nutanix设置中。如果您已经部署了Elasticsearch (ES),您会意识到您的设置是根据您的工作负载进行优化的,但是还有其他设置可以用来优化搜索。下面是我们选择改变的其他设置,以利用Nutanix的操作方式。我们调整的主要设置如下。索引
- index.refresh_interval = 600s.
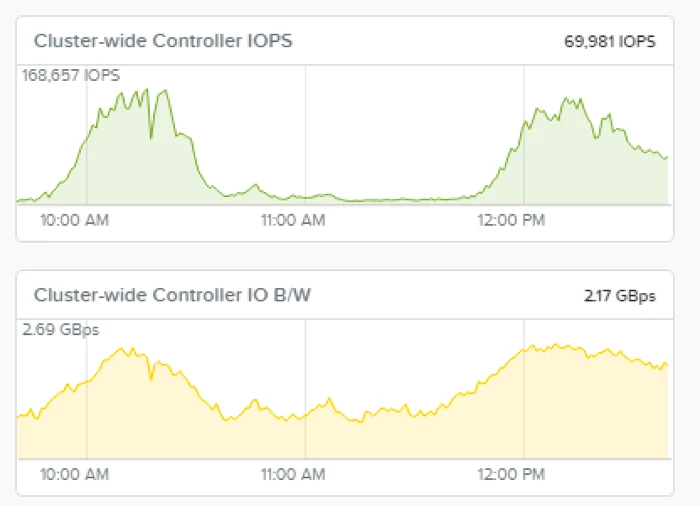
该图显示了何时开始合并。在正常的摄取过程中,写的IOPS可能是10,000 IOPS,但是当合并发生时,您可以看到峰值超过160,000 IOPS,并且吞吐量可以在操作过程中翻倍。
- Index.translog。flush_threshold_size = 1024 mb
大约20%。更改此设置增加了重播单个转变的时间,但性能增益是值得的。
- index.translog.durability =异步
综上所述,总体索引将平均每分钟处理700万个文档,并在峰值时处理高达1100万个文档。对于平均文档级别和2Kb文档大小,主数据的直接写吞吐量约为12GBpm,所有索引数据的直接写吞吐量约为24GBpm。Nutanix集群有足够的吞吐量来处理搜索和上面显示的合并流量。
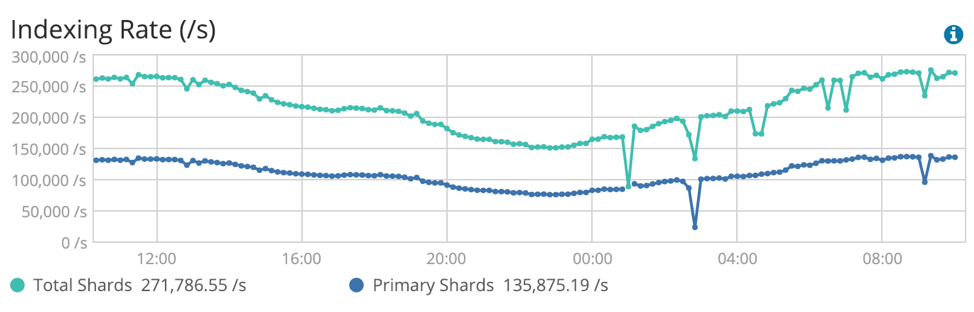
这张来自Kibana的图片显示了白天的交通流量。您可以看到集群每秒处理多少个文档。
搜索
除了正常的搜索优化外,没有真正的建议为您的工作负载执行。Nutanix是一个分布式可伸缩存储平台,为您提供低延迟,如数据位置,如裸机读取。Elasticsearch由于延迟要求推荐本地存储。使用Nutanix的数据点,您可以获得每天执行数百万搜索时所需的低延迟本地读取。失败场景
- Index.translog.retention.size = 10 gb
- Index.unassigned.node_left.delayed_timeout = 15米
这些设置有助于充分利用Nutanix HA来完成关键任务的工作负载。不同之处在于,当一个裸金属节点出现严重故障时,Elasticsearch集群需要几个小时才能恢复为绿色,并使两个分片副本再次可用。而使用Nutanix HA,在节点下降的几分钟内,不活动的索引是绿色的,而活动的索引在30分钟内是绿色的。
这意味着对于裸金属,只有一个副本可以搜索碎片,从而降低了搜索时间。这也增加了IO和网络活动,因为Elasticsearch只做一对一的复制来恢复分片,这意味着一个节点有主副本到新节点,这可能需要几个小时。与此同时,随着Nutanix在后台恢复它的第二个副本,它花费的时间大大减少,因为整个集群都在为重建做出贡献。
对于这个客户来说,一个常见的场景是一个坏驱动器导致了集群中的问题。为了获得最好的性能,裸金属节点选择了RAID 0,这样可以获得最好的吞吐量,但也因为在RAID重建期间,会出现影响整个集群的IO降级。
在这个单个坏驱动器导致节点故障的场景中,Nutanix处理这个问题的方式要优雅得多。我们在Nutanix系统中有多个检查,所以当我们看到一个驱动器的性能下降,或者我们得到SMART错误消息预测驱动器可能会失败,我们将主动停止使用该驱动器或将其从系统中全部弹出。这与裸金属服务器不同,可以防止数据节点故障或单个节点成为性能瓶颈。
数据重建
正如我之前提到的那样,设置是弹星精灵层的单拷贝(RF2),并在Nutanix上的RF2,弹性型搜索副本在两个单独的簇之间分开。Elasticsearch在出现故障时必须创建一个新的副本,当一个副本离线时,它的工作方式是直接的一对一副本。如果您有10个分片来重建,那么这些分片就是从主数据节点到新的辅助节点的一对一复制。如果整个集群很忙,或者它选择的单个节点很忙,那么恢复就会很慢,因此数据的重建就会遇到瓶颈。在此期间,搜索将会变慢,索引可能会遇到瓶颈或面临数据丢失的风险。
如果硬件节点在Nutanix集群中发生故障,它会实现需要复制哪些数据块以恢复绿色。通过这种情况,整个Nutanix群集参与数据的重建,因此在重建时没有超速单个节点,并且您具有群集的分布式计算和IO电源。即使在较重负载期间,这也意味着重建更快。在这种情况下,Elasticsearch还会看到两个副本,以帮助保持搜索劣化。
结论
在查看整个解决方案时,Nutanix将您的大数据应用组合到单个平台上,以实现更好的管理和可扩展性。您可以从此示例中看到,即使是最苛刻的工作负载也可以获得所需的性能。有关运行弹性电池的更多信息,请阅读Nutanix AHV上的弹性堆栈的解决方案注意 -//www.jhbzcj.com/go/virtualizing-elastic-stack-on-ahv.php.您也可以通过发送电子邮件到我们的解决方案专家和服务来设置简报info@nutanix.com..
资源:
- 关于Elasticsearch的Nutanix NEXT社区线程:https://next.nutanix.com/server-virtualization-27/elasticsearch-on-nutanix-31873
- Elasticsearch入门 -https://www.elastic.co/webinars/getting-started-elasticsearch
- Nutanix emoch elasticsearch文档 - https://docs.ech.nutanix.com/integrations/elasic/
©2019 Nutanix,Inc。保留所有权利。Untanix,Nutanix徽标和本文提到的其他Nutanix产品和特征是Nutanix,Inc。的注册商标或商标。本文提到的所有其他品牌名称仅供识别目的,可能是其各自持有人的商标。
 <\/a><\/p>
<\/a><\/p>