



免责声明:该帖子旨在用于演示目的,不得将其视为准备就绪。Nutanix Karbon不包括Velero,因此Nutanix的支持将无法处理与Velero有关的任何情况。
概述
集装箱应用程序的主要原理之一是无状态。原因不是使此应用程序可移植和不依赖任何数据。通过这种方式,您可以在任何平台上重新使用相同的容器映像,并具有相同的结果。
由于容器开始流行,因为可移植性,可伸缩性等,社区找到了一种使用本地存储或共享量的诸如数据库(数据库)(例如数据库)的方法。
恢复无状态应用程序是一个非常简单的过程,您只需要将清单文件重新应用于另一个集群即可。您只需要确保您的清单文件是最新的,并且在群集中运行的最新状态即可。请记住,您不应该直接在群集中进行更改,而应使用新更改更新清单文件,并将其应用于群集。
那州申请呢?好吧,由于使用容器,数据与应用程序解耦,因此备份过程可能有些挑战。有本机命令将您的持续卷的文件系统复制到另一个位置,或使用基础存储的本机功能将数据复制到DR站点。但是,当您想在DR站点中恢复数据时,此过程需要其他任务,并且还取决于您使用的Kubernetes存储插件,您可能还需要导出秘密键才能将存储存储安装在DR中地点。
为了简化无状态和状态应用程序的备份和还原过程,Heptio开发了ARK,现在称为Velero。在此博客中,我们将使用Velero在带有Kubernetes的Nutanix Karbon群集中备份Zookeeper应用程序。备份将被推到Nutanix对象桶中。
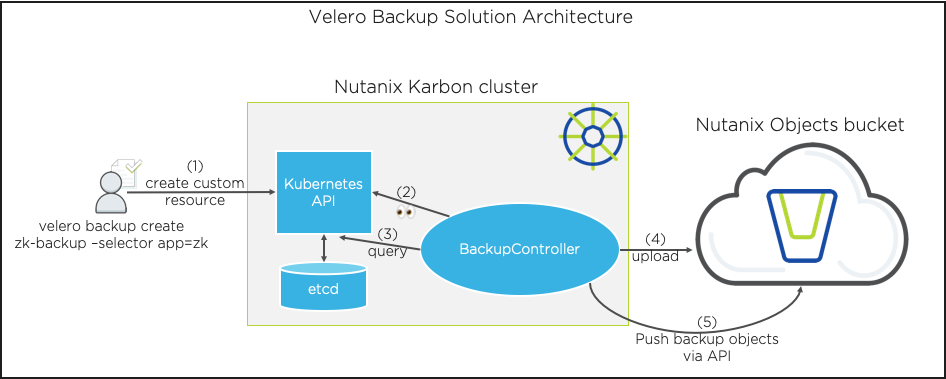
什么是Velero?
[资源:velero github repo这是给予的
Velero(以前是Heptio ARK)为您提供了备份和恢复Kubernetes群集资源和持续数量的工具。您可以使用云提供商或本地运行Velero。Velero让您:
在损失的情况下备份群集并恢复。
将集群资源迁移到其他群集。
将您的生产集群复制到开发和测试簇。
Velero由:
在群集上运行的服务器
当地运行的命令行客户端
Velero支持使用称为Restic的免费开源备份工具来备份和恢复Kubernetes量。这种支持被认为是β质量。请参阅清单限制要了解当前是否适合您的用例。
什么是restic?
[资源:Restic GitHub仓库这是给予的
Restic是一个快速,高效且安全的备份程序。它支持三个主要操作系统(Linux,MacOS,Windows)和一些较小的操作系统(FreeBSD,OpenBSD)。
什么是nutanix对象?
nutanix对象 是一种软件定义的对象存储解决方案,可在降低整体成本的同时不间断地扩展。它采用与S3兼容的REST API接口设计,可将Terabytes处理到非结构化数据的pet,全部来自一个单个名称空间。对象专为备份,长期保留/档案和跨区域DevOps团队而设计。它是Nutanix Enterprise Cloud平台的一部分部署和管理的,消除了需要额外的存储筒仓的需求。
是一种软件定义的对象存储解决方案,可在降低整体成本的同时不间断地扩展。它采用与S3兼容的REST API接口设计,可将Terabytes处理到非结构化数据的pet,全部来自一个单个名称空间。对象专为备份,长期保留/档案和跨区域DevOps团队而设计。它是Nutanix Enterprise Cloud平台的一部分部署和管理的,消除了需要额外的存储筒仓的需求。
使用对象,Nutanix客户可以在现有簇上启用对象存储服务,或设置带有存储密度节点的新群集。
设置
先决条件
一个工作的nutanix对象实例。如果您没有一个,您还在等什么?使用AOS 5.11及以上,每群体免费包含2tib的Nutanix对象。
两个工作的Karbon Kubernetes群集,每个工作人员至少有三名工人。如果您以前从未做过,请看一下这个博客来自我的同事迈克尔·海格(Michael Haigh)。
主要的kubernetes群集称为K8S-Prod。
Kubernetes群集称为K8S-DR。
创建一个水桶
让我们在Nutanix对象中创建一个水桶,Velero将存储备份。
在Prism Central中,单击菜单→服务→对象。
让我们首先创建Velero的访问键。点击访问密钥→增加人数。
选择添加不在目录服务中的人。
您可以使用任何电子邮件地址,我将使用velero@karbon.local。
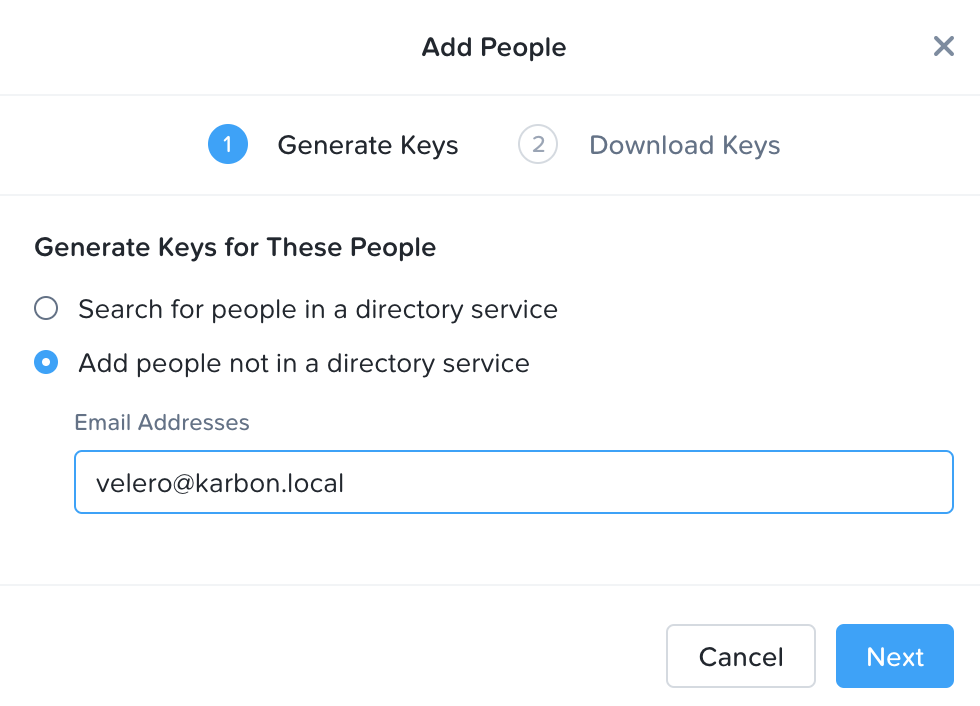
5.单击下一个和下载键。
6.单击关。
7.单击对象存储然后您的对象实例。我的对象实例名称是Theale。

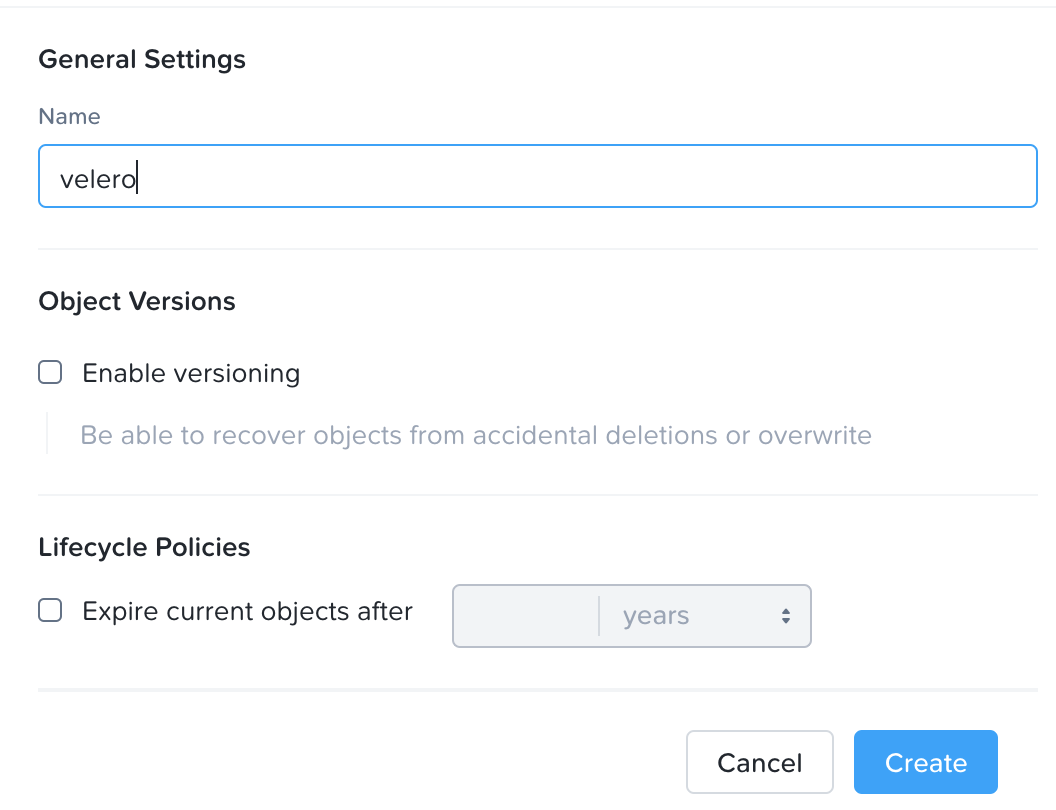
8.单击创建存储桶。
9.例如一个名字,例如velero,然后单击创造。
10.选择velero桶,然后单击分享。
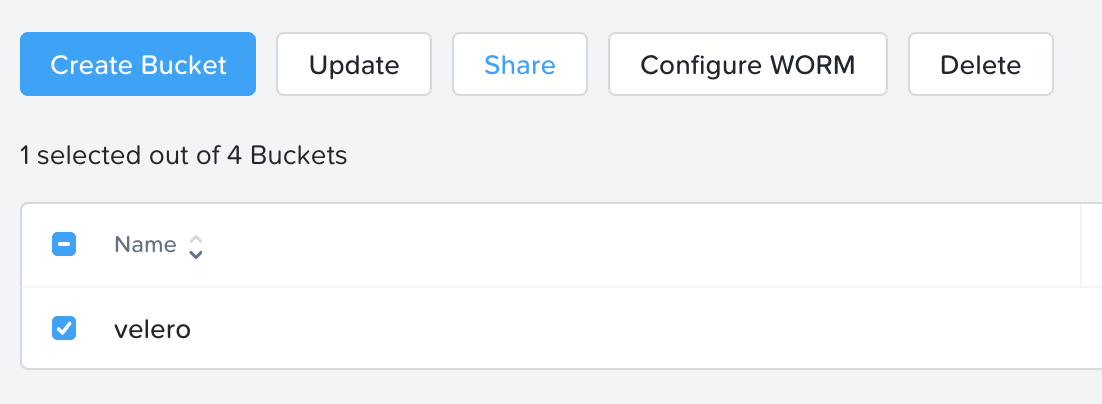
11.搜索您之前创建的用户,并添加读/写权限。
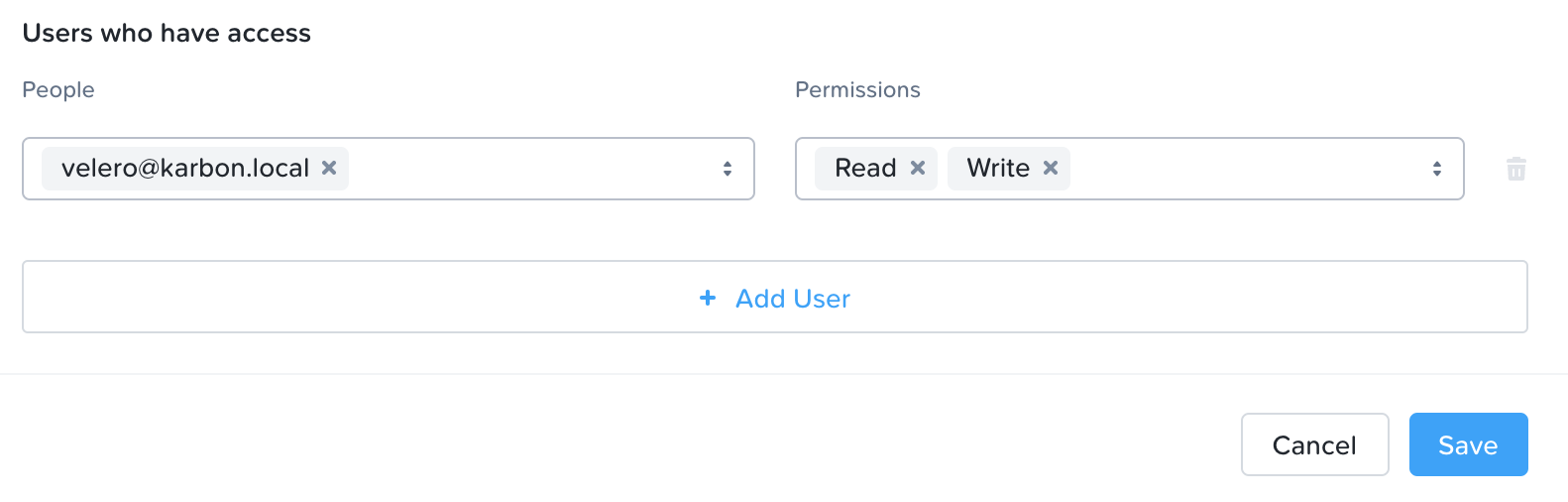
12.单击节省。
Velero准备使用您的水桶!
下载Velero
从您的操作系统下载最新版本的Velero这里。在撰写本博客时,Velero v1.1.0是最新版本。由于我的笔记本电脑是MacBook,我将使用Darwin平台。
安装Velero
1.提取tarball:
tar -xvf <发行射击 - 名称> .tar.gz2.移至您提取tarball的文件夹:
CD velero- <发行射手名>3.创建velero特定的凭据文件(凭证-VELERO)在您的本地目录中。您可以从下载的文本文件中检索键:
VI凭证-VELERO[默认]
aws_access_key_id =
aws_secret_access_key = 在运行安装命令之前,请确保您有一个工作Kubeconfig对于群集,您要安装Velero(首先是K8S-Prod)。您可以使用kubectl验证这一点。
4.安装AWS云提供商的Velero。Nutanix对象是S3 API兼容,Velero将能够使用S3 API调用将备份存储在其上。使用以下命令(请记住将命令替换为nutanix对象IP地址实例):
./velero install \
- 提供AWS \
-bucket velero \
- 销售文件./credentials-velero \
- use-volume-snapshots = false \
-backup-location-config region = us-east-1,s3forcepathstyle =“ true”,s3url = http:// \ \ \ \
- 使用 5.(可选)检查日志以确保没有错误:
kubectl日志部署/velero -n velero现在您有一个工作的Velero部署。
6.在我们可以部署应用程序之前,我们需要更新Restic Daemonset,因为库贝特Karbon部署的Kubernetes群集的宿主路径不同(/var/nutanix/var/lib/kubelet)到Restic Standard HostPath(/var/lib/kubelet)。
kubectl -n velero patch daemonset restic -p ='{“ spec”:{“ template”:{“ spec”:{“卷”:[{“ hostpath”:{“ path”:{“ path”:“/var/nutanix/var/var/var/var/var/var/var/var/var/var/var/var/var/var/var/var/var/lib/kubelet/pods“”,“ type”:“”},“ name”:“ host-pods”}]}}}}}}}}''7. kubernetes博士群集中的步骤4至6。
是时候部署应用程序并测试备份了。
部署应用程序
该示例是使用状态表,poddisruptionbudgets和podantiaffinity的Zookeeper应用程序。状态群的持续量可以保留Zookeeper分布式数据。对于此示例,您需要一个Karbon Kubernetes群集,其中三名工人。
1. Deploy Zookeeper应用程序:
kubectl应用-f https://raw.githubusercontent.com/kubernetes/website/master/master/content/content/en/examples/application/zookeeper/zookeeper/zookeeper.yaml2.以下命令说明了如何将注释添加到要备份的吊舱中。
kubectl annotate pod/your_pod_name backup.velero.io/backup-volumes = your_volume_name_name_1,your_volume_name_2,...就我们的示例而言,由于应用程序是kubernetes状态填充集,因此POD名称是一致的,并且不更改(ZK-0,ZK-1和ZK-2)。该卷相同,名称为datadir对于三个豆荚。
用注释更新三个POD的命令是:
因为我在0 1 2;do kubectl注释pod/zk- $ i backup.velero.io/backup-volumes = datadir;完毕3.在创建备份之前,让我们在Zookeeper应用程序中创建一些数据。
kubectl exec zk-0 zkcli.sh创建 /karbon岩石备份应用程序
1.创建velero备份:
./velero备份创建ZK -selector App = ZK2.检查您的Velero备份状态:
./velero备份描述ZK如果您在nutanix对象中检查桶,您会发现流量有进出。
还原应用程序
让我们恢复备份K8S-DR簇。确保您也在DR集群中安装了Velero。重要的是你有权利Kubeconfig放。
1.获取现有的Velero备份:
./velero备份获取创建的名称状态有效期存储位置选择器
ZK完成2019-10-19 15:18:47 +0100 BST 29D默认应用= ZK
2.列出kubernetes豆荚默认名称空间以确保您没有运行Zookeeper。如果您有一个,请确保您在Kubernetes博士群中。
kubectl获取豆荚找不到资源。3.备份备份:
./velero还原创建-from-backup zk4.检查还原已成功地观看POD,服务和PVC默认名称空间:
kubectl获取豆荚-W名称准备状态重新开始年龄
ZK-0 1/1运行0 1M36S
ZK-1 1/1运行0 1M36S
ZK-2 1/1运行0 1M36S
kubectl得到了全部名称准备状态重新开始年龄
POD/ZK-0 1/1运行0 6M47S
POD/ZK-1 1/1运行0 6M47S
POD/ZK-2 1/1运行0 6M47S
名称类型群集IP外部IP端口年龄
服务/kubernetes clusterip 172.19.0.1 443/tcp 107m
服务/ZK-CS CLUSTERIP 172.19.156.32 2181/TCP 6M47S
服务/ZK-HS群集无 2888/TCP,3888/TCP 6M47S
kubectl获取PVC名称状态量量访问模式Storageclass年龄
datadir-Zk-0绑定PVC-5350C69E-167F-4A94-839E-98E-98E1FBC1EE38 10GI RWO default-storageclass 7M26S
datadir-zk-1绑定PVC-9AEEB4A5-7E8E-411F-AFE8-B8E4E4E5BD3EEB 10GI RWO RWO default-storageclass 7M26S
Datadir-ZK-2绑定PVC-38717562-2B8B-404A-9BBE-F65C65C65FFF8A29 10GI RWO default-storageclass 7M26S5.检查我们在生产中创建的数据Kubernetes群集(karbon岩石)在DR集群中可用:
kubectl exec zk-1 zkcli.sh get /karbon连接到Local主机:2181
2019-10-19 15:09:42,389 [myid:] - 信息[MAIN:环境@100] - 客户端环境:Zookeeper.version = 3.4.10-39D3A4F2693333C922ED3DB283BE479BBE479F9DAECAA0F,建立在[...]上[...]
。
。
。
[...]
2019-10-19 15:09:42,503 [myid:] - info [main-sendthread(localhost:2181):clientcnxn $ sendthread@1299] - 会话在服务器localhost/0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:0:1:2181,sessionID = 0x26DE48881A0E0000,协商超时= 30000
观察者::
观察者状态:综合类型:无路径:null
岩石
CZXID = 0x10000000E
ctime =星期六10月19日14:56:50 UTC 2019
mzxid = 0x10000000e
mtime =星期六10月19日14:56:50 UTC 2019
PZXID = 0x10000000E
cversion = 0
dataversion = 0
aclversion = 0
临时者= 0x0
datalength = 5
numchildren = 0结论
应该尽可能多地推动备份来使用应用程序内置功能,而不是用于基础架构专有机制。这将确保您保持不可知论,并且无论您在何处运行应用程序,都可以使用相同的过程。
但是,如果您没有其他选择,并且仍然想对整个Kubernetes群集,名称空间或任何特定的Kubernetes对象进行备份,那么Velero是实现此目标的绝佳方法。Nutanix对象用S3 API兼容的存储桶补充Velero,以存储和还原备份。
 \u00a0\u00a0<\/p>
\u00a0\u00a0<\/p> is a software-defined object storage solution that non-disruptively scales-out while lowering overall costs. It\u2019s designed with an S3-compatible REST API interface to handle terabytes to petabytes of unstructured data, all from a single namespace. Objects is designed for backup, long term retention\/archiving, and cross-region devops teams. It\u2019s deployed and managed as part of the Nutanix Enterprise Cloud Platform, eliminating the need for additional storage silos.<\/p>
is a software-defined object storage solution that non-disruptively scales-out while lowering overall costs. It\u2019s designed with an S3-compatible REST API interface to handle terabytes to petabytes of unstructured data, all from a single namespace. Objects is designed for backup, long term retention\/archiving, and cross-region devops teams. It\u2019s deployed and managed as part of the Nutanix Enterprise Cloud Platform, eliminating the need for additional storage silos.<\/p> <\/p>
<\/p> <\/p>
<\/p> <\/p>
<\/p> <\/p>
<\/p> <\/p>
<\/p> <\/p>
<\/p>