

我对此没有任何骨头,AWS中的裸机节点很昂贵。如果我们想节省资金并拥有与AWS的DR,那么问题将如何使节点的数量保持较小,直到我们故障转移?
在AWS中,所有Nutanix规则仍然适用。我们至少需要一个三节点群集才能开始。如果我们有足够的存储容量,我们可以继续接受本地群集的复制,而不必担心CPU和内存约束。您也可以使用本地AHV支持的备份软件直接备份到S3。然后,当您发生停电时,您可以在AWS中快速构建一个Nutanix群集,并开始将数据还原到该群集。
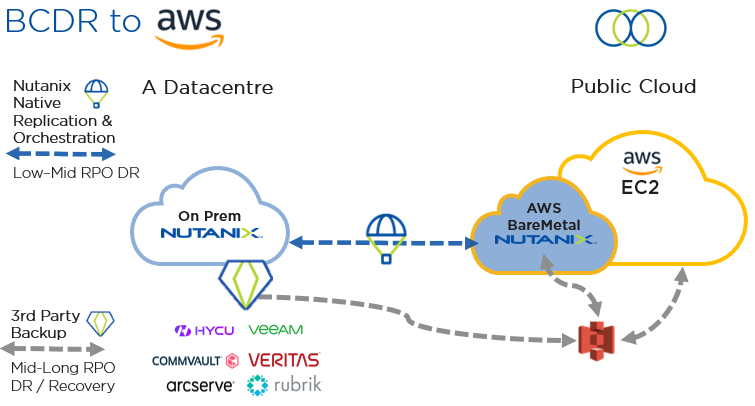
我被要求自动化在AWS中将节点添加到小Nutanix群集中的过程,然后使用LEAP(DR Runbooks)和X-Play(自动化事件和警报的动作)在Prism Central(PC)中启动故障转移。以下视频是我想到的。
此处列出了从集群门户中添加通过API添加节点的代码:
https://github.com/dlessner/clustersaddnode/blob/main/addnode.py
您可以更改要添加的节点的数量,也可以多次拨打电话。
API呼吁跳跃 - 恢复计划可能有些艰巨。有一种简单的方法来获取代码。在Google Chrome中,如果您打开开发人员工具(CTRL+Shift+i),并且按下故障转移按钮时,您将看到批处理API请求。一般部分将为您提供API呼叫,如果您查看解析部分,则有效载荷部分将具有API主体。从这里,您只需要将代码复制并经过X播放,就可以在路上。
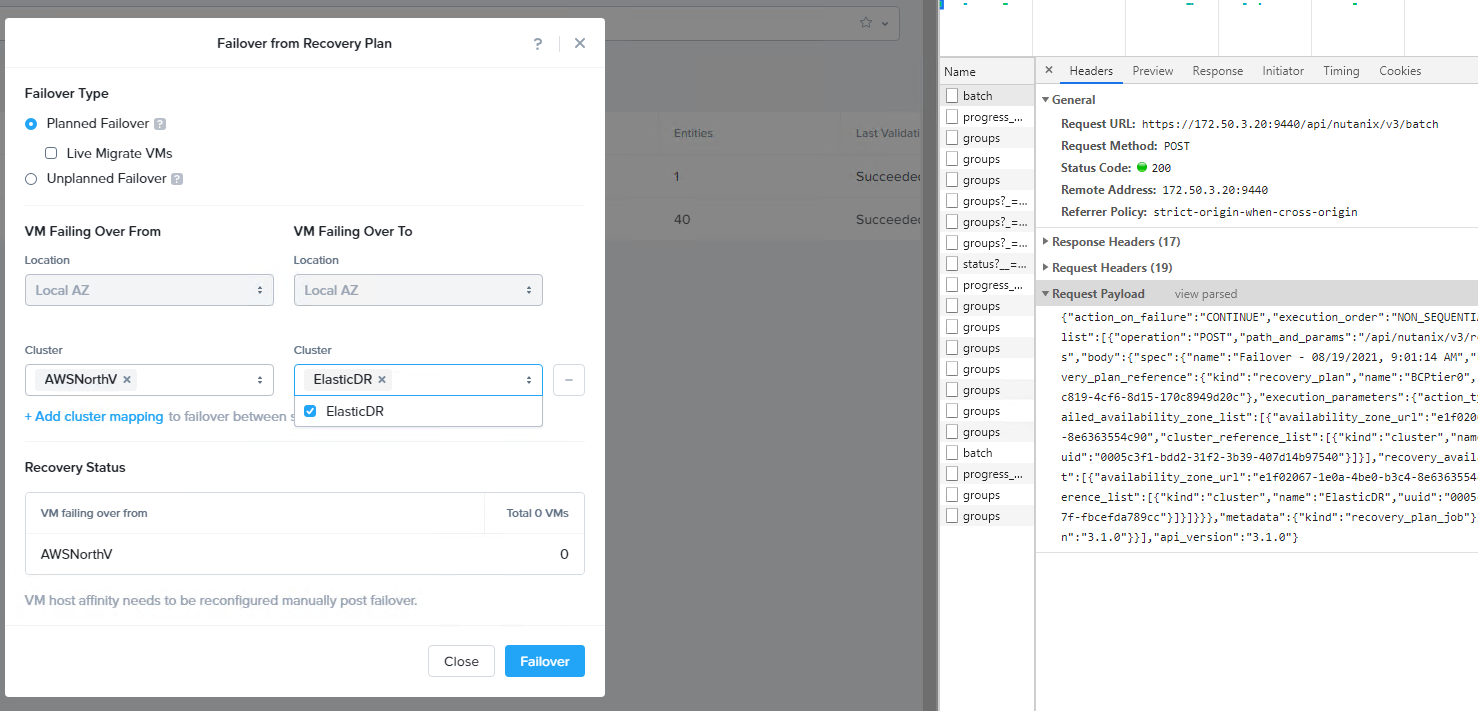
一旦我将在视频中做出的不同之处就是在群集服务下降时将事件更改为开火。确实有100种不同的方法可以做到这一点。我认为要重点是群集门户网站有API,X-Play在响应事件和警报方面确实很灵活。当您结合两者时,会发生魔术。
如果您有疑问,请发表评论。
快乐的乌云。

