



本文旨在更好地解释警报的细微差别“控制器VM上一个或多个磁盘的磁盘空间使用”如棱镜所见我包括一些基本的故障排除步骤来确定确切的问题。
SSH进入集群的任何CVM,并运行以下命令:
++ allssh“ df -h”这将列出由CVM控制的所有磁盘的使用%。
对于例如:请参阅下面的屏幕截图
Nutanix为其基础架构的SSD /Home保留空间,并限制为40GB,有时可能会在空间使用情况下运行较低并触发警报。
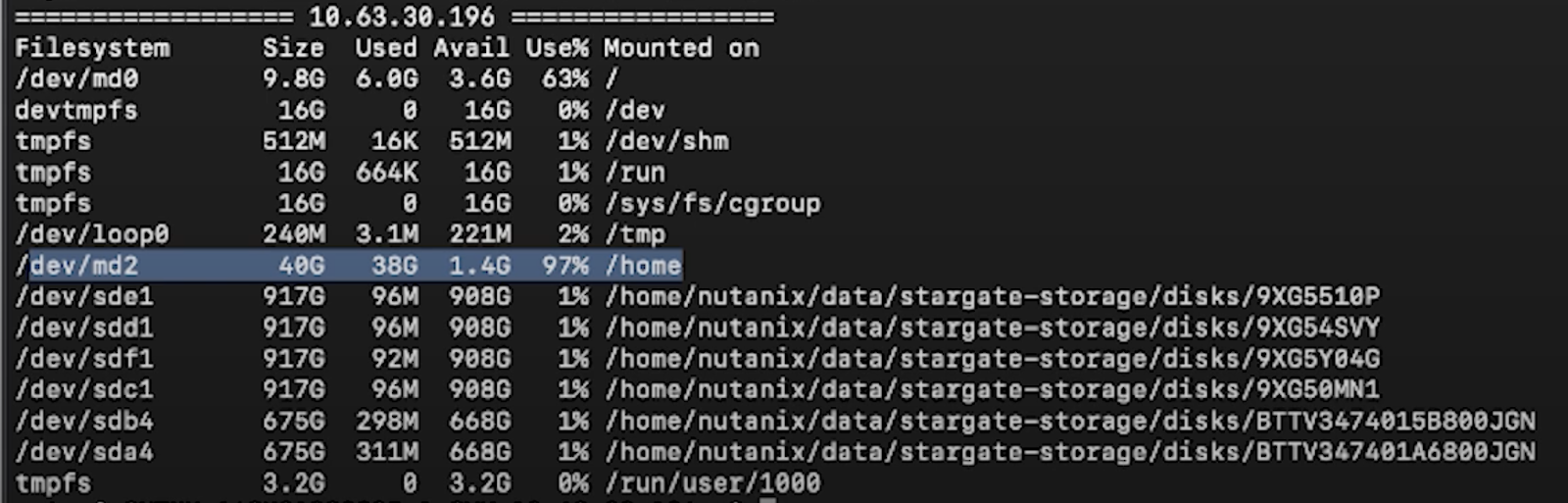
查看本文以获取有关如何减少的更多信息/家庭空间用法。
其他磁盘 /DEV /SDX是每个节点上的单个物理驱动器。首先,我们通过运行SMARTCTL检查来消除驱动器有故障的可能性。
++ sudo smartctl -a /dev /sdx用DF -H输出中的适当磁盘名称替换X。
如果SMARTCTL测试失败,请与您的供应商联系以进行磁盘更换。
回到DF -H输出,这些磁盘的空间使用%可以为我们提供有关警报的更多信息。
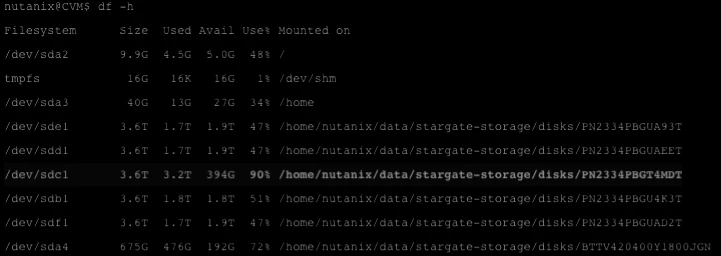
确定SSD驱动器:
如果SSD驱动器显示出更多的95%使用情况,则意味着R/W IO的速率比冷数据分层快得多,或者通过Prism将某些用户VM固定在Flash SSD层上。
基本上,我们需要研究可能增加SSD磁盘尺寸或检查任何具有闪存模式的VM,该VM正在为所有SSD磁盘空间带来。
参与Nutanix的支持是进一步分析或在此处发布您的评论和输出的情况,以便社区有机会。
HDD驱动器利用 %根据所影响的磁盘的未磁盘为我们提供一些其他信息。
如果所有磁盘在一个CVM中显示高百分比,则策展人服务在这个节点上可能没有做工作。
但是,如果只有一个磁盘显示高使用%,那么我们需要检查磁盘本身的内容以找到问题。
有关更多故障排除和分辨率:请参阅KB 3224- 故障排除有关HDD用法的“磁盘空间使用率高”警报
群集宽 - 可见高磁盘空间的使用:
在这种情况下,必须调查警报,因为星际之门在该磁盘上的范围已满95%时停止将数据写入磁盘。当群集上的所有磁盘均达到95%的利用率时,拒绝了从管理程序中的写操作,这可能会导致VMS悬挂。
磁盘空间的利用是由于用户数据引起的,这表明群集相对于存储容量的尺寸不足。这也可能是由于需要进一步故障排除的各种与AOS相关的问题。
策展人扫描
策展人负责很多事情,但是它所做的主要工作之一是收集垃圾和清理。
这使策展人负责在磁盘上收回空间。如果策展人扫描没有成功,则可能不会收回磁盘空间。
假设您删除VM或虚拟磁盘,仅标记用于删除。策展人服务在策展人部分扫描或FULLS扫描过程中清除VDISK。
另一种情况可能是策展人扫描同步复制后未删除快照的结果。
命令检查在集群中运行的最新策展人扫描:
++ curator_cli get_last_successful_scans如果最近6小时没有策展人扫描,请联系Nutanix支持
有关策展人扫描的更多信息:
KB -2101在什么条件下,策展人扫描运行?
一些进一步的故障排除步骤以确定警报的原因:
++ NCLI PD LS-SNAP显示任何已过期但尚未从群集中删除的快照
++ vdisk_config_printer |grep to_remove |WC -L检查标记为删除但尚未清除的VDisks检查。
++ ncc health_checks hardware_checks disk_checks disk_usage_check验证是否有任何单独的磁盘或控制器VM(CVM)系统分区使用量超过一定阈值。
有关策展人扫描的更多信息:KB-1523
 <\/span><\/p>
<\/span><\/p>